一说到 CSS 盒模型,这是很多小伙伴耳熟能详的知识,甚至有的小伙伴还能说出 border-box 和 content-box 这两种盒模型的区别。
但是一说到 CSS 包含块,有的小伙伴就懵圈了,什么是包含块?好像从来没有听说过这玩意儿。

好吧,如果你对包含块的知识一无所知,那么系好安全带,咱们准备出发了。

包含块英语全称为containing block,实际上平时你在书写 CSS 时,大多数情况下你是感受不到它的存在,因此你不知道这个知识点也是一件很正常的事情。但是这玩意儿是确确实实存在的,在 CSS 规范中也是明确书写了的:
https://drafts.csswg.org/css2/#containing-block-details

并且,如果你不了解它的运作机制,有时就会出现一些你认为的莫名其妙的现象。
那么,这个包含块究竟说了什么内容呢?
说起来也简单,就是元素的尺寸和位置,会受它的包含块所影响。对于一些属性,例如 width, height, padding, margin,绝对定位元素的偏移值(比如 position 被设置为 absolute 或 fixed),当我们对其赋予百分比值时,这些值的计算值,就是通过元素的包含块计算得来。
来吧,少年,让我们从最简单的 case 开始看。

<body>
<div class="container">
<div class="item"></div>
</div>
</body>
.container{
width: 500px;
height: 300px;
background-color: skyblue;
}
.item{
width: 50%;
height: 50%;
background-color: red;
}
请仔细阅读上面的代码,然后你认为 div.item 这个盒子的宽高是多少?

相信你能够很自信的回答这个简单的问题,div.item 盒子的 width 为 250px,height 为 150px。
这个答案确实是没有问题的,但是如果我追问你是怎么得到这个答案的,我猜不了解包含块的你大概率会说,因为它的父元素 div.container 的 width 为 500px,50% 就是 250px,height 为 300px,因此 50% 就是 150px。
这个答案实际上是不准确的。正确的答案应该是,div.item 的宽高是根据它的包含块来计算的,而这里包含块的大小,正是这个元素最近的祖先块元素的内容区。
因此正如我前面所说,很多时候你都感受不到包含块的存在。
包含块分为两种,一种是根元素(HTML 元素)所在的包含块,被称之为初始包含块(initial containing block)。对于浏览器而言,初始包含块的的大小等于视口 viewport 的大小,基点在画布的原点(视口左上角)。它是作为元素绝对定位和固定定位的参照物。
另外一种是对于非根元素,对于非根元素的包含块判定就有几种不同的情况了。大致可以分为如下几种:
- 如果元素的 positiion 是 relative 或 static ,那么包含块由离它最近的块容器(block container)的内容区域(content area)的边缘建立。
- 如果 position 属性是 fixed,那么包含块由视口建立。
- 如果元素使用了 absolute 定位,则包含块由它的最近的 position 的值不是 static (也就是值为fixed、absolute、relative 或 sticky)的祖先元素的内边距区的边缘组成。
前面两条实际上都还比较好理解,第三条往往是初学者容易比较忽视的,我们来看一个示例:
<body>
<div class="container">
<div class="item">
<div class="item2"></div>
</div>
</div>
</body>
.container {
width: 500px;
height: 300px;
background-color: skyblue;
position: relative;
}
.item {
width: 300px;
height: 150px;
border: 5px solid;
margin-left: 100px;
}
.item2 {
width: 100px;
height: 100px;
background-color: red;
position: absolute;
left: 10px;
top: 10px;
}
首先阅读上面的代码,然后你能在脑海里面想出其大致的样子么?或者用笔和纸画一下也行。
公布正确答案:
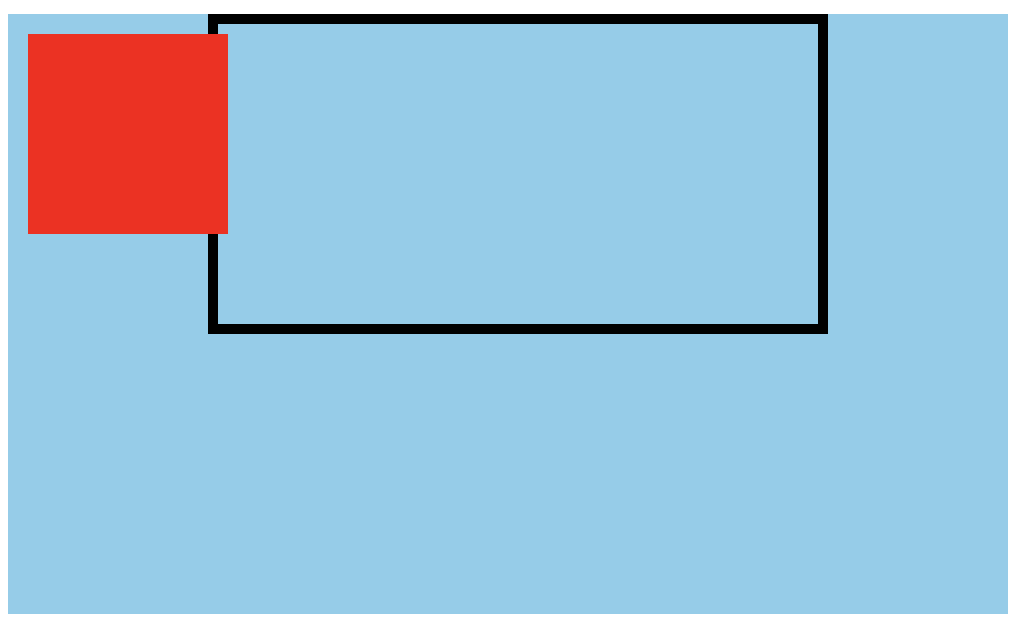
怎么样?有没有和你所想象的对上?
其实原因也非常简单,根据上面的第三条规则,对于 div.item2 来讲,它的包含块应该是 div.container,而非 div.item。
如果你能把上面非根元素的包含块判定规则掌握,那么关于包含块的知识你就已经掌握 80% 了。
实际上对于非根元素来讲,包含块还有一种可能,那就是如果 position 属性是 absolute 或 fixed,包含块也可能是由满足以下条件的最近父级元素的内边距区的边缘组成的:
- transform 或 perspective 的值不是 none
- will-change 的值是 transform 或 perspective
- filter 的值不是 none 或 will-change 的值是 filter(只在 Firefox 下生效).
- contain 的值是 paint (例如: contain: paint;)
我们还是来看一个示例:
<body>
<div class="container">
<div class="item">
<div class="item2"></div>
</div>
</div>
</body>
.container {
width: 500px;
height: 300px;
background-color: skyblue;
position: relative;
}
.item {
width: 300px;
height: 150px;
border: 5px solid;
margin-left: 100px;
transform: rotate(0deg); /* 新增代码 */
}
.item2 {
width: 100px;
height: 100px;
background-color: red;
position: absolute;
left: 10px;
top: 10px;
}
我们对于上面的代码只新增了一条声明,那就是 transform: rotate(0deg),此时的渲染效果却发生了改变,如下图所示:

可以看到,此时对于 div.item2 来讲,包含块就变成了 div.item。
好了,到这里,关于包含块的知识就基本讲完了。

我们再把 CSS 规范中所举的例子来看一下。
<html>
<head>
<title>Illustration of containing blocks</title>
</head>
<body id="body">
<div id="div1">
<p id="p1">This is text in the first paragraph...</p>
<p id="p2">
This is text
<em id="em1">
in the
<strong id="strong1">second</strong>
paragraph.
</em>
</p>
</div>
</body>
</html>
上面是一段简单的 HTML 代码,在没有添加任何 CSS 代码的情况下,你能说出各自的包含块么?
对应的结果如下:
| 元素 | 包含块 |
|---|---|
| html | initial C.B. (UA-dependent) |
| body | html |
| div1 | body |
| p1 | div1 |
| p2 | div1 |
| em1 | p2 |
| strong1 | p2 |
首先 HTML 作为根元素,对应的包含块就是前面我们所说的初始包含块,而对于 body 而言,这是一个 static 定位的元素,因此该元素的包含块参照第一条为 html,以此类推 div1、p1、p2 以及 em1 的包含块也都是它们的父元素。
不过 strong1 比较例外,它的包含块确实 p2,而非 em1。为什么会这样?建议你再把非根元素的第一条规则读一下:
- 如果元素的 positiion 是 relative 或 static ,那么包含块由离它最近的块容器(block container)的内容区域(content area)的边缘建立。
没错,因为 em1 不是块容器,而包含块是离它最近的块容器的内容区域,所以是 p2。
接下来添加如下的 CSS:
#div1 {
position: absolute;
left: 50px; top: 50px
}
上面的代码我们对 div1 进行了定位,那么此时的包含块会发生变化么?你可以先在自己思考一下。
答案如下:
| 元素 | 包含块 |
|---|---|
| html | initial C.B. (UA-dependent) |
| body | html |
| div1 | initial C.B. (UA-dependent) |
| p1 | div1 |
| p2 | div1 |
| em1 | p2 |
| strong1 | p2 |
可以看到,这里 div1 的包含块就发生了变化,变为了初始包含块。这里你可以参考前文中的这两句话:
- 初始包含块(initial containing block)。对于浏览器而言,初始包含块的的大小等于视口 viewport 的大小,基点在画布的原点(视口左上角)。它是作为元素绝对定位和固定定位的参照物。
- 如果元素使用了 absolute 定位,则包含块由它的最近的 position 的值不是 static (也就是值为fixed、absolute、relative 或 sticky)的祖先元素的内边距区的边缘组成。
是不是一下子就理解了。没错,因为我们对 div1 进行了定位,因此它会应用非根元素包含块计算规则的第三条规则,寻找离它最近的 position 的值不是 static 的祖先元素,不过显然 body 的定位方式为 static,因此 div1 的包含块最终就变成了初始包含块。
接下来我们继续修改我们的 CSS:
#div1 {
position: absolute;
left: 50px;
top: 50px
}
#em1 {
position: absolute;
left: 100px;
top: 100px
}
这里我们对 em1 同样进行了 absolute 绝对定位,你想一想会有什么样的变化?
没错,聪明的你大概应该知道,em1 的包含块不再是 p2,而变成了 div1,而 strong1 的包含块也不再是 p2 了,而是变成了 em1。
如下表所示:
| 元素 | 包含块 |
|---|---|
| html | initial C.B. (UA-dependent) |
| body | html |
| div1 | initial C.B. (UA-dependent) |
| p1 | div1 |
| p2 | div1 |
| em1 | div1(因为定位了,参阅非根元素包含块确定规则的第三条) |
| strong1 | em1(因为 em1 变为了块容器,参阅非根元素包含块确定规则的第一条) |
好了,这就是 CSS 规范中所举的例子。如果你全都能看明白,以后你还能跟别人说你是看过这一块知识对应的 CSS 规范的人。

另外,关于包含块的知识,在 MDN 上除了解说了什么是包含块以外,也举出了很多简单易懂的示例。
具体你可以移步到:https://developer.mozilla.org/zh-CN/docs/Web/CSS/Containing_block
好了,这就是有关包含块的所有内容了,你学会了么?-)
-EOF-